Unix has been around for more than 50 years, and the original design principles must be good enough for it (and its derivative, Linux) to be the most widely used Operating System on the planet – 80% of servers, most supercomputers, and the most deployed OS (Android). It is also the most popular OS on Mars!
Much of Unix’s success can be attributed to the “Unix Philosophy” which can be very briefly summarised as:
- Write programs that do one thing and do it well
- Write programs to work together
- Write programs to handle text streams, because that is a universal interface
Programs that do one thing are easy to understand, and simple to test. Key to the Unix philosophy is how modules can be composed – the Unix way is generally that all modules communicate with each other using a protocol that they can all understand – text, and various meta-protocols can be layered over the top of text e.g. columns and fields (separated by space, comma etc.), and connected together using pipes.
The above simple rules allow a system to be composed of simple components, connected together, and for significantly complex application behaviour to emerge as a result. The canonical example of the power of the Unix Philosophy is the famous Knuth vs McIlroy competition to build a word count program; McIlroy builds a six command shell pipeline that is a complete (and bug-free) solution to the problem.
The Unix philosophy in Enterprise IT
The above has arguably never really translated to Enterprise IT – an Enterprise application tends to deal with relatively complex problems, be made up of modules with a greater scope and business functionality, and despite numerous attempts over the years to try and come up with a high performance standard for connection of modules together (COM, CORBA, SOAP, JSON/REST/HTTP anyone?), an effective standardised connection mechanism has never “stuck”.
The Chronicle solution
Chronicle’s solution for the Unix Philosophy in Enterprise IT involves composing systems from
- Programs that do one thing and do it well – single-threaded Java¹ microservices
- Connected together with a mechanism to transport structured and self-describing data – Chronicle Queue plus Chronicle Wire Method Readers and Writers
These open source technologies not only provide the benefits of Unix tools plus pipes, but also
- Are low latency and low garbage, and thus are suitable for building systems that require high throughput, microsecond response times and predictable latencies.
- Persist all data that is sent between modules, facilitating debugging, troubleshooting and out-of-band reporting
- Allow individual modules to be stopped/restarted/upgraded without interrupting others
Example
Below is some example code that is a super-simplified version of a workflow that is common in the world of financial markets (most of Chronicle’s users are in this space):
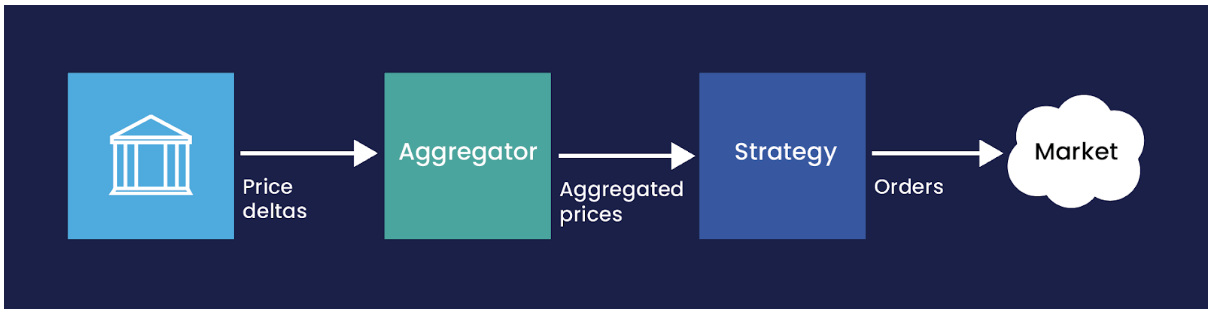
order pipeline
In this example
- an exchange emits a lot of fast-moving price data which are sent to…
- an aggregator which assembles price deltas into a “book” of prices which are sent to..
- a strategy which decides whether an order should be sent to…
- the market
The exchange simulator, aggregator and strategy are implemented as single-threaded microservices – these are extremely simple and do not depend on Chronicle Queue or Chronicle Wire. The inputs and outputs of each microservice are defined as Java interfaces – each microservice implements its input interface and composes its output interface, and these interfaces in turn refer to Java DTOs which are sent between the microservices.
For the aggregator service the interfaces look like this:
public interface AggregatorOut { void marketDataSnapshot(MarketDataSnapshot mds); }
And
public interface AggregatorIn { void mdi(MarketDataIncrement mdi); }
In this simple example there is only one method on each, but a service can implement many interfaces with many methods and any number of arguments of all kinds, including primitives.
One of the DTOs is:
public class MarketDataSnapshot extends SelfDescribingMarshallable { private String symbol; @LongConversion(MicroTimestampLongConverter.class) private long transactTime; private double bid; private double ask; // getters/setters ... }
And the microservice:
public class AggregatorImpl implements AggregatorIn { private final Map<Long, MarketDataSnapshot> md = new HashMap<>(); private final AggregatorOut out; public AggregatorImpl(AggregatorOut out) { this.out = out; } @Override public void mdi(MarketDataIncrement mdi) { MarketDataSnapshot aggregated = md.computeIfAbsent(mdi.symbol(), MarketDataSnapshot::new); // trivially simple aggregation and book build if (mdi.side() == BuySell.buy) aggregated.bid(mdi.price()); else aggregated.ask(mdi.price()); aggregated.transactTime(mdi.transactTime()); if (aggregated.valid()) out.marketDataSnapshot(aggregated); } }
You can see that there is no dependence on any Chronicle code, with the exception of the DTO, and the microservice respects the Unix philosophy – it is simple and easy to understand, and does Just One Thing. Chronicle Wire Method Readers take care of reading incoming events from the “in” queue and dispatching these to the “in” interface methods, and Chronicle Wire Method Writers ensure that when the service calls a method on the “out” interface, the method call is serialised and written to the out queue.
All input and output to/from the service is serialised to/from Chronicle Queues using BinaryWire which is compact, efficient, fast and zero-garbage and yet still self-describing, so its data can be read by any other microservice or tool – you can see this by trying to run the examples and the “tailf” command below.
All this code can be found in the Chronicle-Queue-Demo/md-
The DTO extends a Chronicle Wire class SelfDescribingMarshallable, which provides functionality including:
- Automatic serialisation using Chronicle’s Wire and Bytes Marshallable strategies
- Automatic conversion to/from friendly YAML format using Chronicle Wire
- Transparent support for versioning – new fields can be added to a DTO and old fields removed without causing breakages, and code can be plugged in to convert from an older version to a new version
- Support for renderers e.g. transactTime is a microsecond timestamp stored efficiently as a long but rendered to the user by the MicroTimestampLongConverter to a friendly date/time string
- A path from greatest convenience (Chronicle Wire) to lowest possible latency (Bytes Marshallable) – our recommendation is to start with the SelfDescribingMarshallable’s implementation of Wire serialisation and you can incrementally convert DTOs in the fast path to use Bytes Marshallable
Testing
The microservice leverages the above functionality, and Chronicle Wire’s YamlTester to allow very simple behaviour-driven YAML testing – the test class looks like this:
public class AggregatorTest { public static void runTest(String path) { YamlTester yt = YamlTester.runTest(AggregatorImpl.class, path); assertEquals(yt.expected(), yt.actual()); } @Test public void strategy() { runTest("aggregator"); } // more tests ... }
And the “aggregator” folder contains an in.yaml file
--- mdi: { symbol: BTCUSD, transactTime: 2019-12-03T09:54:37.345678, rate: 23418.5, side: buy } --- mdi: { symbol: BTCUSD, transactTime: 2019-12-03T09:54:38, rate: 23419.5, side: sell }
Which the YamlTester plays into the AggregatorImpl class, automatically deserialising the MarketDataIncrement DTOs and dispatching them to the mdi method. This is all done in a single thread, allowing breakpoints to be set. The YamlTester records any output sent to the “out” interface and compares it to the contents of the out.yaml file. Intellij shows a friendly text diff in case of failure, making it very easy to see what was changed:
--- # nothing in here as the first incoming MDI does not produce an output --- marketDataSnapshot: { symbol: BTCUSD, transactTime: 2019-12-03T09:54:38, bid: 23418.5, ask: 23419.5 } ...
Hooking it all up and running
The sample code contains maven exec java stanzas to run each microservice and also stanzas to run the ChronicleReaderMain tool which reads messages from the queues, deserialises them and displays them as YAML. To run:
Start up three terminal screens and run the following in the md-pipeline directory to start the services
mvn exec:java@generate mvn exec:java@aggregator mvn exec:java@strategy
And to watch the output from each service start up three more screens (these are the equivalent of Unix tee and tail -f)
mvn exec:java@tailf -Dqueue=agg-in mvn exec:java@tailf -Dqueue=agg-out mvn exec:java@tailf -Dqueue=strat-out
Conclusion
We can see that it is possible to realise the Unix Philosophy in Enterprise IT using a strongly-typed Enterprise language (Java), a suitable component technology (microservices) and an appropriate mechanism to glue them together (Chronicle Queue & Wire).
Note that if you want more features you can talk to info@chronicle.software about commercial extensions – Chronicle Services – which provide the following features:
- HA & DR
- Sophisticated restart and replay strategies
- IoC runtime
- Health monitoring and latency stats
- Services visualisation
- Configuration
- Timers
—