Introduction
In a previous article we saw how Chronicle Services uses a model based on events to support the maintenance of key elements of state in a service. In this article we will examine how this state is initialised when a service starts for the first time, or restarts following an outage, both planned and unplanned.
Service Startup and Event Replay
When a Chronicle Services component is started, or restarted, there will normally be a requirement to construct (or reconstruct) state so that it has the same values as when the component was stopped.
Since we have all the input events processed by the service to construct the state when the service stopped, we can recreate this state by replaying all of these events through the appropriate event handlers. The events are read from the queues and replayed in order, but not in “real time” (i.e. without the delays between the events). Additionally, no output events are posted from the handlers during a replay when the state is updated, as this would cause inconsistencies in the operation of downstream services.
Chronicle Service provides a number of ways in which event replay can be performed, known as Restart Strategies.
These are managed through the service’s configuration, in particular using three configuration parameters:
startFromStrategy Defines the point at which a service begins processing input events “for real”
inputsReplayStrategy Defines from where events used to construct state are read
snapshotQueue Used when a service has output snapshots of its state to a queue, forming the starting point for reconstructing that state.
The default behaviour is that no state construction is performed, and input events are processed starting from the point at which the last output event was posted (in the case of a service starting for the first time, this will cause processing to begin with the first input event)
Basic Event Replay from Input
The simplest strategy for reconstructing a service’s state is for the service to read and process all events from a single input queue. As an example, let’s look at a simple service:
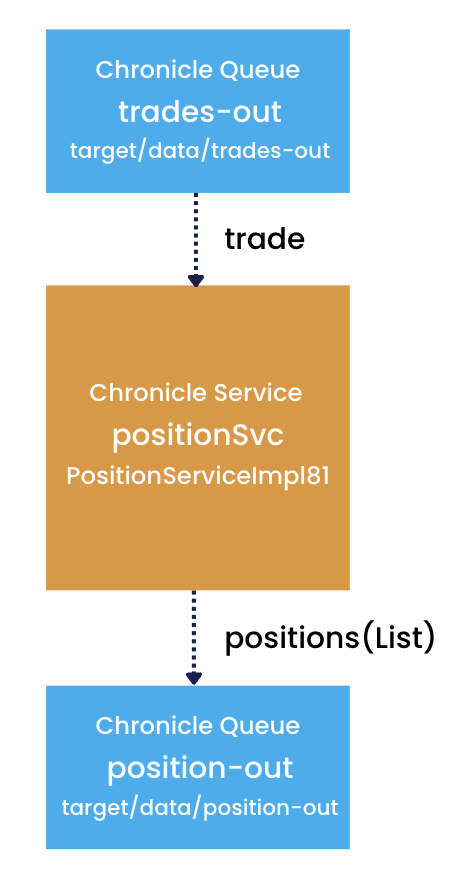
The service is called positionSvc, and accepts events indicating trades (posted to the trades-out queue by some other service) and uses them to update a list of positions. Whenever a trade is processed, the updated list of positions is posted as an event on the service’s output queue, position-out, from where other interested services can see the change(s).
As with other Chronicle Services applications, the configuration of this service is represented in a YAML file, below is an excerpt of this configuration:
positionSvc: {
inputs: [ trades-out ],
output: position-out,
startFromStrategy: START,
inputsReplayStrategy: INPUTS,
# …
}
The configuration parameters instruct the service to read and process all events (startFromStrategy: START) from the input queue (inputsReplayStrategy: INPUTS) of the service when it is starting up – in this case, from the trades-out queue. The events are processed by the service’s event handler(s). However, by default, output events that reflect state changes are not posted to the output queue until the replay is completed and the service begins “normal” processing of new events. Note: this behaviour can be changed using a further configuration parameter if required.
But when does “replay” stop and “normal” processing of events begin? It is tempting to think that replay behaviour should stop when all input events have been read and processed. However, it is possible that another service (or services) may have posted events to the input queue while this service was stopped. If the service simply replayed all events in the input queue, then there is a chance that events the service has not seen will simply be replayed, updating the state locally but not notifying these changes to downstream services.
To avoid this race condition, a service will change from replaying input events to treating them as “real” input when it reaches an event whose messages index indicates that it was posted after the last event that was posted to the output queue, a marker known as LAST_WRITTEN. Note that this behaviour assumes that service state updates are accompanied by the posting of such output events.
Event Replay from Multiple Input Queues
The basic example above showed how a service can reconstruct state using events on a single input queue. In reality, however, many services take input from multiple input queues. In these cases, a slightly different approach is needed. Chronicle Services guarantees to replay events from a single queue in order, however when there are multiple queues, the interleaving of events across these queues is not guaranteed.
To illustrate this, let’s add a second input queue to the example from above:
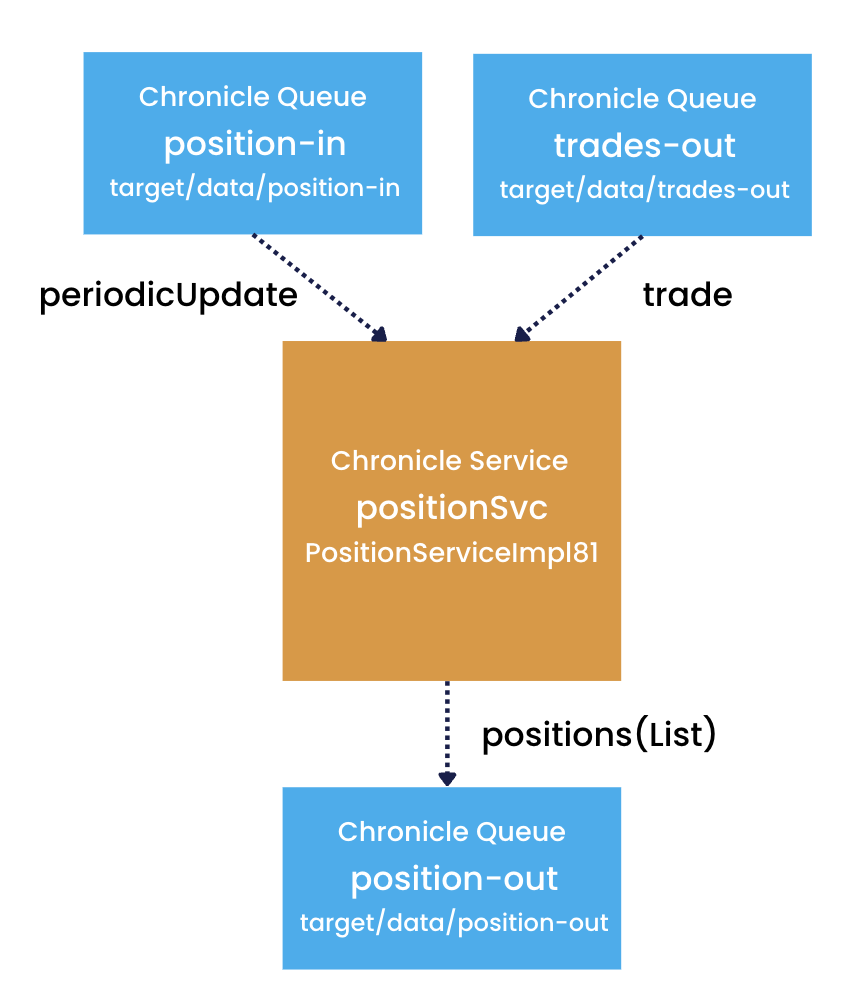
This is very similar to the example shown above, but here the positionSvc has an additional input queue, position-in, used to send timer events at regular intervals to the service.
Messages from each input queue are read and processed on a separate thread. In normal operation, the queues are processed on a round-robin basis.
If state is to be reconstructed during startup, events from an individual queue are guaranteed to be processed in the same order as when they originally occurred. To ensure that the order of processing of events from different queues is also maintained, Chronicle Services uses a small amount of metadata, carried by events, containing the “source” queue of the event and the time when it was read from this queue. As a result, state updates that occur in a cumulative fashion from different input queues are guaranteed always to yield the same resulting state.
To ensure this behaviour, a slightly different service configuration is used:
positionSvc: {
inputs: [ position-in, trades-out],
output: position-out,
startFromStrategy: START,
inputsReplayStrategy: OUTPUT,
# …
}
The inputReplayStrategy configuration element is set to the value OUTPUT.
Initialising State from Output Events
Chronicle Services applications are often deployed into high throughput environments and may run for extended time periods. As a result, the overhead of initialising state following a restart by replaying input events can be significant (Chronicle Queue sizes are often measured in hundreds of gigabytes).
Remember, however, that a service will usually post an event to its output queue when significant state changes occur. Many services incorporate a significant amount of state information in these events. This provides an opportunity to take a different approach to initialising state following a restart, which looks at output events as a form of snapshot of state – perhaps partial but often complete.
In this strategy, messages from the output queue are read in reverse order (i.e. most recent message first). The service is required to implement a handler that uses state information in the event to recreate the state. The service must also provide logic to stop the replay process once it is satisfied that all state has been recreated.
Let’s enhance the previous example to illustrate this:
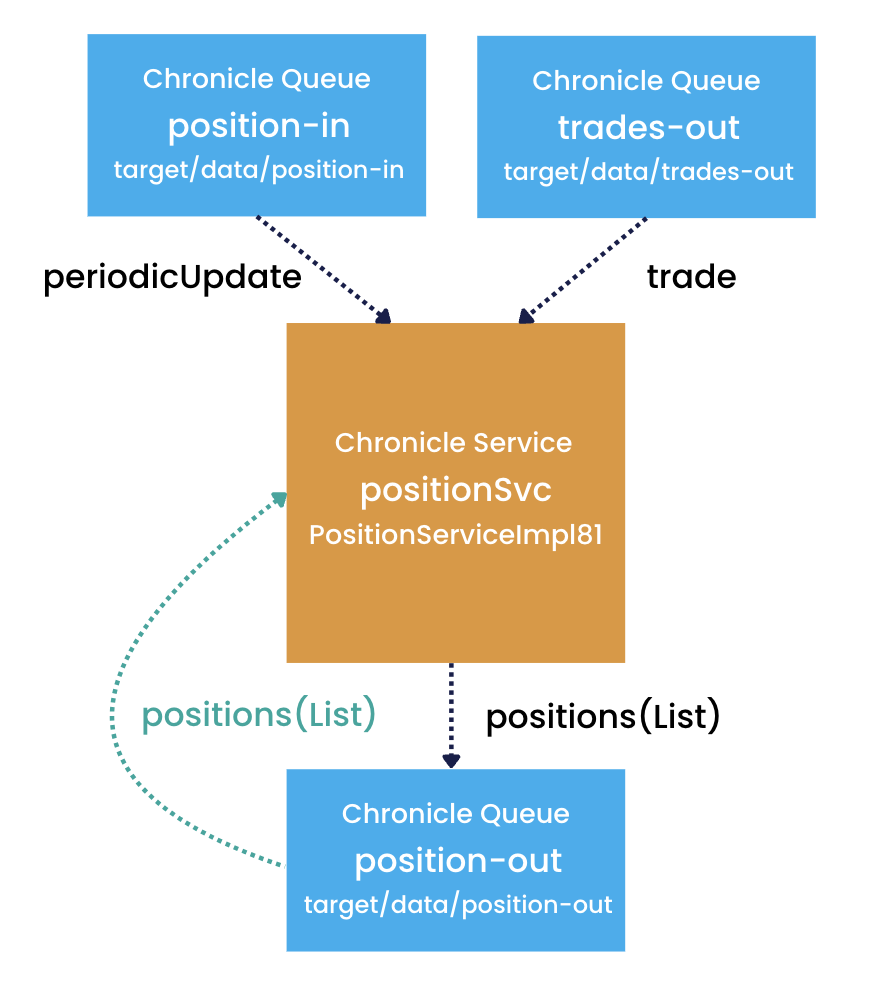
Notice there is a path for the service to consume events from its output queue during initialisation.
Once again, the service configuration selects this replay strategy:
positionSvc: {
inputs: [ position-in, trades-out],
output: position-out,
startFromStrategy: LAST_WRITTEN,
inputsReplayStrategy: OUTPUT_REVERSE,
# …
}
The inputsReplayStrategy value OUTPUT_REVERSE indicates that the service will read events in most-recent-first order from its output queue and replay them until satisfied that its state has been completely reconstructed. Once that has been done, the startFromStrategy value LAST_WRITTEN indicates that the service should begin processing input events that arrived after the most recent event on the output queue (this would have been the first event examined in the replay). In some cases, this value can be set to END, which begins the processing of input events that arrive only after initialisation is complete.
Unlike the previous strategies, this approach requires the service itself to be implemented slightly differently.
- The service should be designed so that state changes are always reflected in output events (this is a guideline from Event-Driven Architecture in any case).
- The service should have an event handler that processes relevant output events as if they were input, using the information from the event payload to update the service state.
- The service should implement a method that can verify if all elements of state have been initialised, so that the replay process can be stopped.
In the positionSvc, if we assume that the state we are recreating is a list of positions, and that when a position changes the relevant output event contains the entire list, then we can recreate the state by processing just one of these output events. Compared to the alternative of reading through all input events, this represents a significant reduction in overhead.
Using Snapshots to Optimise State Reconstruction
As we saw before, it is possible that a service may require a large amount of state to support its operation, and may perform frequent updates to elements of this state at regular intervals over a long period of time, leading to an extremely large number of events to replay when restarting after the service has been stopped.
One way to mitigate this is to take a different approach to persisting state, based on periodically outputting an event that contains the values of all the mutable state elements in the service. A common approach is to write these “snapshot” events based on Chronicle Services PeriodicUpdate events.
When constructing state following a restart, the service will search backwards through time from end of its output queue until it locates the most recent snapshot event. This provides starting values for the state elements, and by replaying events following this we will arrive at the values of these elements when the service stopped much more quickly than by the earlier methods.
SnapshotSource
Introducing state snapshots is straightforward, and allows service developers to define their own types and logic to implement the functionality. There is no need to configure the startFromStrategy or inputsReplayStrategy properties. A service implementation should simply implement a specific interface, SnapshotSource, and the runtime will invoke the necessary functionality.
The SnapshotSource interface declares a single method that positions the queue at the index of the most recently written snapshot event. The type of this snapshot event is left to the developer; it is passed as an argument to the method implementation. An event handler for the snapshot event type needs to be provided, to set the state data to the values represented in the event’s DTO.
Idempotent Key Value Store
Although extremely flexible, the SnapshotSource approach described above still requires work from the developer. In many cases a standardised approach will suffice, and for this Chronicle Services provides the IdempotentKeyValueStore (IKVS). IKVS is a key-value store that presents a Map-like interface to its clients, but uses a Chronicle Queue to receive events whenever an element is updated.
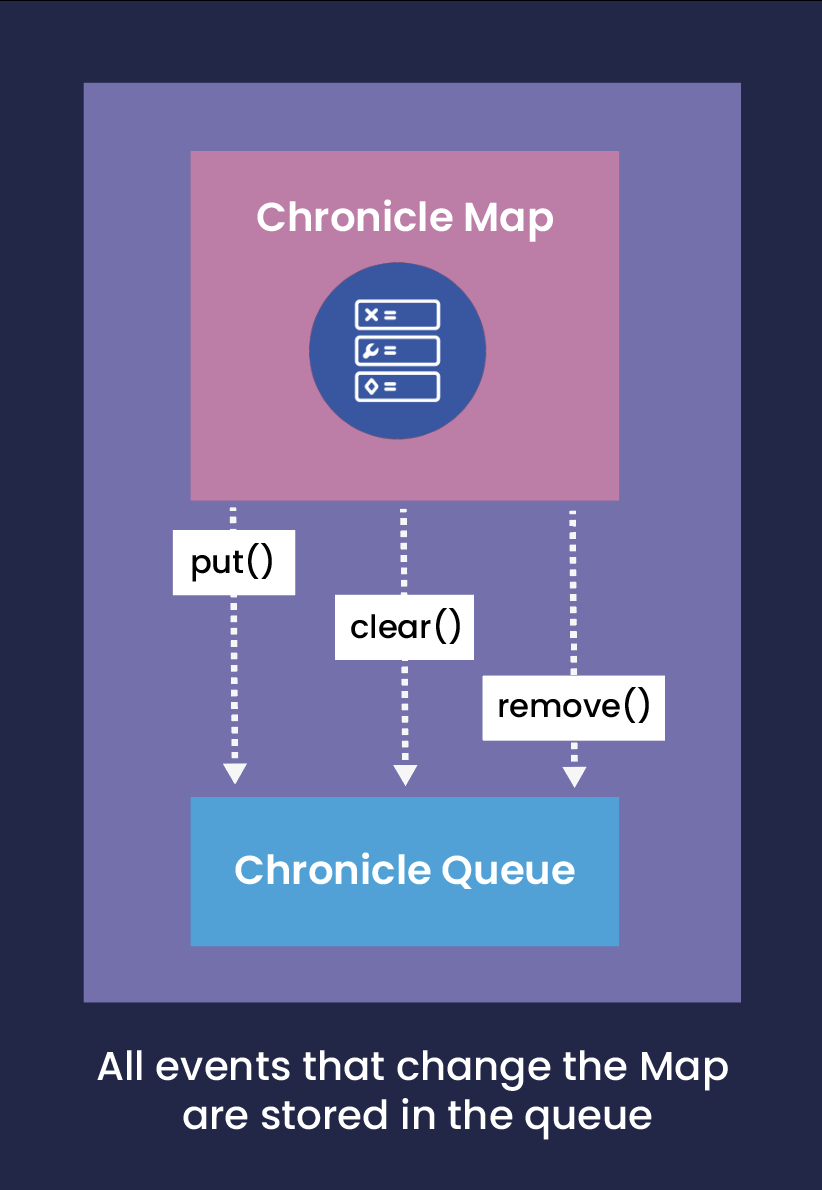
In some ways, we can consider IKVS as an Event-sourced Map.
There are many advantages to using IKVS to manage mutable state, discussed in detail in the Chronicle Services documentation. However, here, we are focussing on its use of the SnapshotSource approach to state management described above.
The IKVS should encapsulate all of the mutable state elements in a service. Updates to these elements will be posted as events to the specified queue (which will be the output queue for the service). Additionally, snapshots of the state in the IKVS are posted at regular intervals (usually controlled using periodicUpdate events). So, when reconstructing state from the queue, it is necessary to replay only those events from the last such snapshot (since a Map will only hold the most recent value for each key).
If the IKVS contains a large number of entries, writing a snapshot of the entire IKVS could take some time, and stall the processing of business logic events. To counter this, the IKVS configuration allows each snapshot to contain only a subset of the elements.
The IKVS map is divided into chunks, called batches, which are written to the queue as snapshots. During state reconstruction following a restart, event processing starts from the beginning of the most recent snapshot, meaning we replay only the most recent updates, usually from the preceding few minutes rather than hours, days, or even weeks.
The diagram below shows how this works.
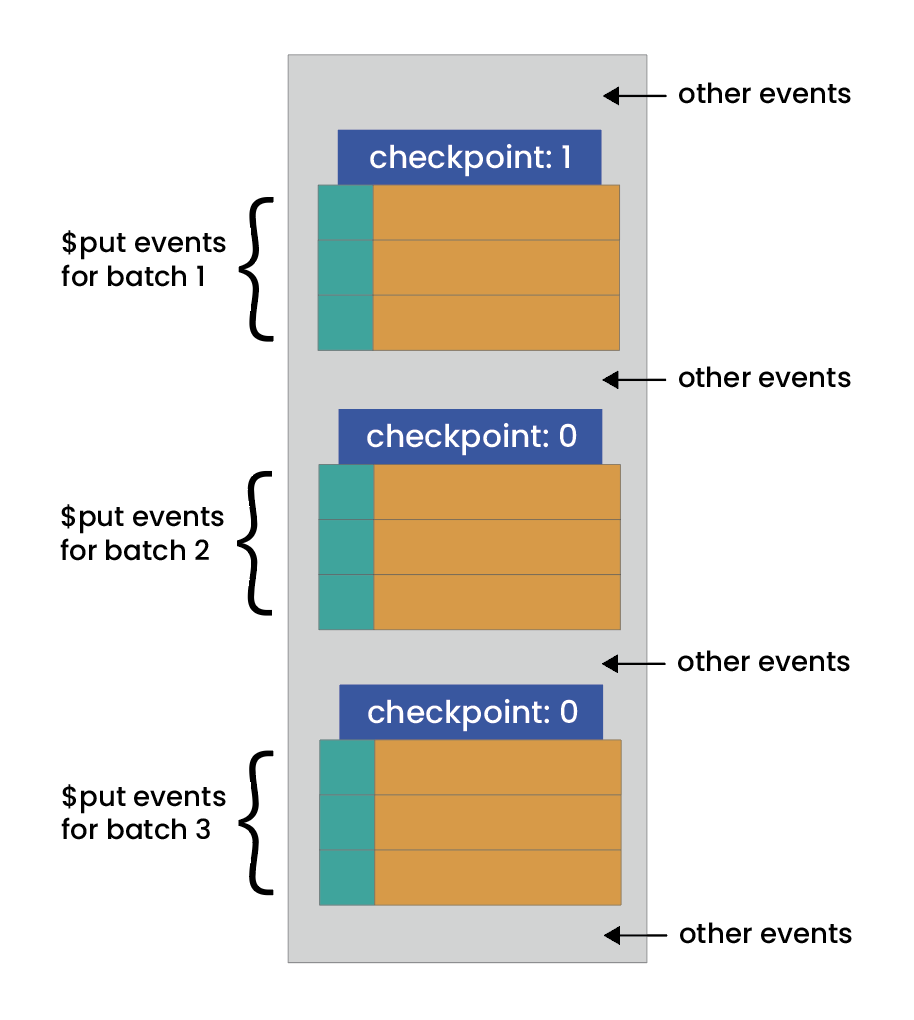
If the service has not been running for long enough to persist the entire state of the Map, then all events from the start of the queue will be replayed.
From a configuration point of view, the snapshotQueue element acts as a hook to which specific code to setup the IKVS can be attached – its value is the output queue for the service:
service-c: {
inputs: [ out ],
output: queueC,
snapshotQueue: queueC,
periodicUpdateMS: 2000,
# …
}
The service uses periodicUpdate events to signal the writing of checkpoints every 2 seconds. The size of each chunk is set when the IKVS is initialised.
Summary
Managing state is critically important to the correct functioning of any Microservice-based application. Chronicle Services offers a variety of approaches, that remove the need to use costly database management systems in the majority of cases but meet the goals of reliable availability of state in the presence of many different starting or restarting scenarios.
When used in conjunction with Chronicle Queue’s replication capabilities, they also form the basis of a highly flexible set of capabilities for implementing High-Availability applications that can operate effectively in distributed environments.
Further Reading
More information about State Management in Chronicle Services can be found in the Services Reference Guide.
Examples of the different approaches to event replay to recreate state in a service described in this article, including how to utilise IdempotentKeyValuStore, can be found in the Chronicle Services Cookbook.