Over the years at Chronicle, we have built a large number of applications and systems that are focused around low latency messaging, primarily in the financial sector. During this time, we have found that following certain architectural principles has helped us build these applications more efficiently, and we have ended up with more robust, reliable and maintainable software as a result.
Chronicle Services is a framework that distills many of these ideas and facilitates interaction with various aspects of the Chronicle software stack to achieve our goals and those of our customers.
In this series of articles, we will explore Chronicle Services through a number of worked examples, each illustrating a specific feature of the framework.
An application built with the Chronicle Services framework consists of a number of loosely coupled processing components known as services, which communicate with each other using asynchronous messaging, following the Event Driven Architecture.
An event is an immutable indication that something has happened. One or more services may be interested in the event and will handle it in their own way. Handling an event will normally involve posting a new event, once again this will indicate that the event has been handled and may include data indicating any state changes.
A service may maintain local state and Chronicle Services follows the principles of events sourcing to manage this state. Local state in a service can be capable of being reconstructed from the events that it has handled or generated using one of a variety of strategies. We will examine this in more detail later.
What’s in a Service?
A Service is a self-contained processing component that accepts input from one or more sources and outputs to a single sink. Let’s look at a simple example where a service performs a simple operation (addition) on a pair of numbers and outputs the result. The service can be illustrated in the following diagram:
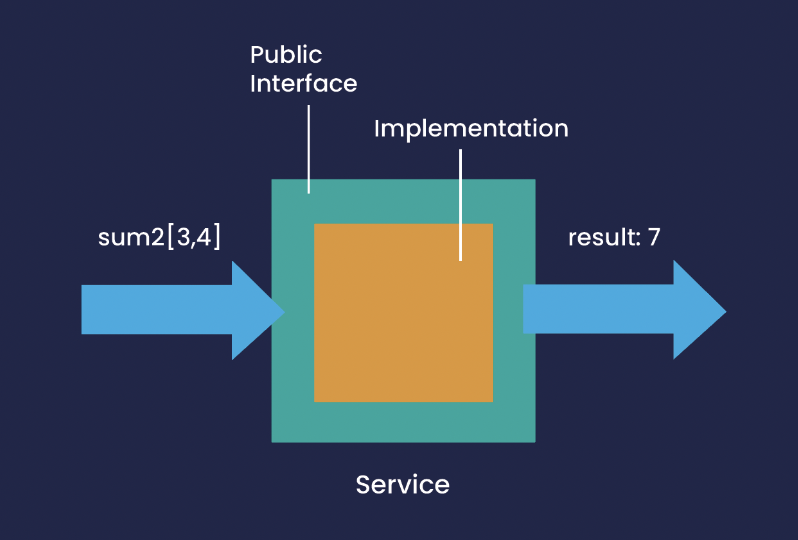
The service has a single input, from which it reads input events of type sum2, each of which carries a payload consisting of two numbers to be added together. It also has a single output, to which it will post an event carrying a single number, which is the result of performing the addition of the two input values.
The service has a public interface that defines the details of the input events it is interested in, and the format of the output events that it will emit. This is all that is required to interact with the service, the implementation of the event handler is hidden.
Service API
Chronicle Services expects the input and output event details to be encapsulated in Java interfaces. There can be zero or more input interfaces, but there must be exactly one output interface. For example, in the service shown above:
public interface SumServiceIn { void sum2(double x, double y); } public interface SumServiceOut { void sumResult(double value); }
The method names correspond to the message types that are expected or generated. Chronicle Services is based on unidirectional asynchronous message passing, so the handler methods do not return any value.
Service Implementation
The class that implements the service is defined as follows:
public class SumServiceImpl implements SumServiceIn { private static Logger LOG = LoggerFactory.getLogger(SumServiceImpl.class); private SumServiceOut out; public SumServiceImpl(SumServiceOut out) { this.out = out; } @Override public void sum2(double x, double y) { LOG.info("Processing sum(" + x + "," + y + ")"); out.sumResult(x + y); } }
The class implements the input API interface. This requires it to implement methods to handle each of the incoming event types.
The class also maintains a reference to an object that implements the output API, the details of which are injected at construction time by the Services framework.
Handling Events
The Chronicle Services runtime will dispatch the event to the appropriate handler method for the incoming event type. Once processing is complete, the output event is generated by calling the appropriate method on the output API.
The mappings of incoming event to method invocation and method invocation to outgoing event is handled by Chronicle Services, based on the API interface types. No additional information is required, and the mechanism used is highly efficient both in terms of time and memory usage.
Interacting with a Service
In order to interact with a service, we need to post events to its input and read events from its output. The service does not place any specific requirements on the transport used to manage event transmission, although the default implementation is based on Chronicle Queue, a messaging system with ultra-low latency capabilities. Throughput of over 1 million events per second is possible using Chronicle Queue.
It is also possible to utilise a different event transport without any modifications to the service. This is especially useful for functional testing, and Chronicle Services provides a powerful testing framework for doing this. We will examine the Chronicle Services approach to testing in a later article.
For now, we can illustrate a complete application that generates input to the Sum Service and consumes its output events. The application can be shown diagrammatically:
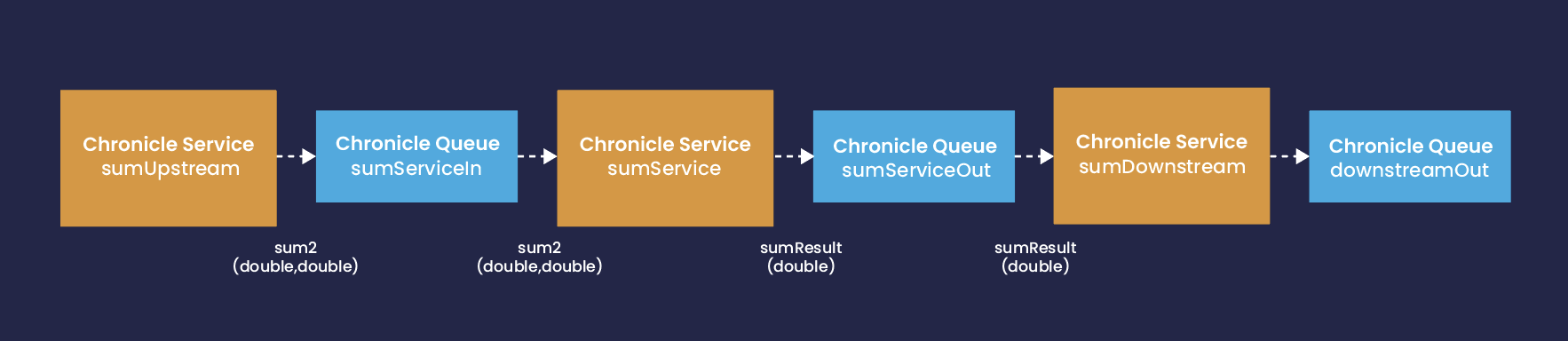
Data flows through the application from left to right. The services are connected using Chronicle Queues. The leftmost service is known as an upstream service. It generates events of the appropriate type and posts these to the input queue of the Sum Service. Output events from the Sum Service are posted to its output queue and consumed by the rightmost service, known as the downstream service. Any output events from the downstream service are posted to a sink queue that simply consumes the event with no processing or output.
One of the strengths of Chronicle Services is the ability to specify this application structure declaratively and have the instances of each component created automatically when the application starts. To do this, we use a configuration file in YAML to describe the services and the queues that they use for communication. This file is normally called services.yaml. Here is the file that describes the application shown in the diagram:
ChronicleServicesCfg { queues: { sumServiceIn: { path: data/sumServiceIn }, sumServiceOut: { path: data/sumServiceOut }, downstreamOut: { path: data/downstreamOut }, }, services: { sumService: { inputs: [ sumServiceIn ], output: sumServiceOut, implClass: !type software.chronicle.services.ex1.services.sumservice.impl.SumServiceImpl, }, sumUpstream: { inputs: [ ], output: sumServiceIn, implClass: !type software.chronicle.services.ex1.services.upstream.impl.SumServiceUpstream, }, sumDownstream: { inputs: [ sumServiceOut ], output: downstreamOut, implClass: !type software.chronicle.services.ex1.services.downstream.impl.SumServiceDownstream, } } }
First we define the queues. In this simple example, all that is required for each queue is the pathname to the directory where the files for queue persistence are stored. More details on the configuration of Chronicle Queues can be found here.
Then we define the services. In each case, the input queue(s) and output queue are specified, together with the fully qualified class name of the service’s implementation class. For both queues and services, there are many more configuration elements that can be set. We will discover these in later articles.
The upstream service, sumUpstream, posts a message to its output queue (which is the main Sum Service input queue) requesting a single calculation. The result of this calculation is posted to the Sum Service output queue, which is the input queue of the downstream service, sumDownstream. The downstream service simply logs the receipt of the message. It does not post an output event, since it is intended to act as a sink service.
Deploying and Running the Application
Single Process
Our application can be deployed as a single Java process, with all three services running (in separate threads). This is useful for development and integration testing. To do this, we need to provide an entry point for execution to start. This is done in the usual way, using a main() method, which can be encapsulated in a class also called Main:
public class Main { public static void main(String[] args) throws InterruptedException { ThreadRunner.runAll("services.yaml"); Thread.sleep(3_000); } }
Like most event-based frameworks, Chronicle Services uses an event loop as the basis for execution. The event loop monitors the specified input queue(s) for incoming events and dispatches these to the relevant handlers. It is initialised and started using the call to ThreadRunner.runAll(), to which we pass the name of the file that contains the configuration information as shown above.
The default behaviour is for each service to have its own event loop, each running on a separate thread. All events for a given service are handled within this thread so that implementations of event handlers can assume a single-threaded execution environment. This simplifies handlers significantly, with benefits to maintainability and performance.
All the event loop threads are, by default, set up to be daemon threads. This means that they will be shut down automatically when all non-daemon threads in the process terminate. In our example, the only non-daemon thread is the main thread. We therefore pause this thread for 3 seconds before main() returns and the thread terminates (stopping all services).
When the application is run, the Chronicle Services runtime uses the information from the configuration file to initialise each service. Output will contain a lot of log messages, we will look at the most significant for this example. First, the Chronicle Services banner message:

The main processing chain can be seen, from the posting of the initial command by the upstream service to the final logging of the result by the downstream service:
… [main/sumUpstream] INFO UpstreamSvcImpl - Sending sum2(3, 7) [main/sumUpstream] INFO Runner - runInitializationComplete [main/sumUpstream] INFO RunLoopControllerMain - running sumUpstream... [main/sumDownstream] INFO Runner - runInitializationComplete [main/sumDownstream] INFO RunLoopControllerMain - running sumDownstream... [main/sumService] INFO Runner - runInitializationComplete [main/sumService] INFO RunLoopControllerMain - running sumService... [main/sumService] INFO SumServiceImpl - Processing sum(3.0,7.0) [main/sumDownstream] INFO DownstreamSvcImpl - Result: 10.0
Multiple Processes
Production deployments will normally be based around multiple processes, with each process running a single Chronicle Service. This can be achieved without changing the Service code or configuration. We do, however, require a separate entry point for each process. Each Main class can be similar to the example shown above for the single process deployment, however they are based on a different method to start the service:
ThreadRunner.runService("services.yaml", service-name);
where service-name is the identifier for the service descriptor in the configuration file.
The Chronicle Services runtime will ensure, as before, that the Chronicle Queue instances are created if necessary and that the service establishes contact with the queue so that communication can take place. Given that Chronicle Queue is based on shared memory for inter-process communication, the different services need to be located on the same physical system.
It is still possible to deploy services to different hosts, however, and we will see how this can be done in future articles.
Containers
A further option is to deploy applications in OCI containers, such as Docker containers, either in the single or multiple process model, allowing flexibility of deployment into on-prem or cloud based environments.
With the multi-container approach, it is possible to deploy and run the application easily with tools like Docker Compose. More sophisticated orchestration tools like Kubernetes allow deployment of services-based applications into cloud based clusters.
What’s Next?
In the next article we will look in more detail at how data is sent between services as the payload of events. Chronicle Services utilises an extremely efficient mechanism for encoding and decoding structured data into messages.
Later articles will examine:
- how services can be tested using the Chronicle YamlTester framework, and how this allows testing approaches based on business logic.
- the way in which services may be configured using the external, declarative approach introduced here but also using APIs allowing this to be managed at runtime and Inversion of Control techniques.
- how to interact with Chronicle Services applications from “outside” the Chronicle Services runtime.
- approaches to managing state in a service
- how a service runs, and how it is possible to parameterise event loop behaviour when required to improve latency.
- different approaches to deployment, including how to build and deploy cloud-native applications using Chronicle Services.
- Chronicle Services’ approach to implementing High Availability systems, including deployment of services into a cluster with guaranteed replication of events to ensure no loss of data and minimal time overhead in the event of failure of one or more components.
and more…
Links:
Documentation: Services Cookbook
Website: Chronicle Services