Have you realised that 99% of your system’s latency might be due to accidental complexity?
In this article we will look at a real life example of accidental complexity in the context of latency to help explain what it is, and will provide a strategy for how to investigate how you can reduce potential accidental complexity and increase your system’s performance.
Essential vs Accidental Complexity
Firstly, as the two are often confused, let’s clarify the difference between essential and accidental complexity:
Essential complexity is inherent in the problem that is being solved, the complexity we can’t avoid as it is part of what the software is aiming to address. e.g. the time it takes to send an event from A to B.

Accidental complexity is the complexity that is not inherent in the problem, but rather in the solution. This is the complexity that is not fundamental and can be removed or reduced with a better design or technology choice.

Real-Life Example of Accidental Complexity
If we look at getting from St. Paul’s Cathedral to Shakespeare’s Globe in London in two different ways we can grasp what accidental complexity is all about.
Driving requires an indirect route, and has parking challenges in both places:

Image 1. Driving from St. Paul’s Cathedral to Shakespeare’s Globe in London
Walking on the other hand offers a more direct route, and hence minimises accidental complexity:

Image 2. Walking from St. Paul’s Cathedral to Shakespeare’s Globe in London
Visualising Accidental Complexity in Low Latency Systems
In the previous example it was easy to grasp accidental complexity, but in the realms of low-latency systems, where latencies are invisible, it can be more difficult to understand. One way to make latencies more tangible would be to translate latencies into distances.
For instance, Kafka’s 99th percentile latency in a round-trip benchmark that took 2.6 milliseconds is the equivalent of sending a signal from New Haven to Washington, which is 330 miles:
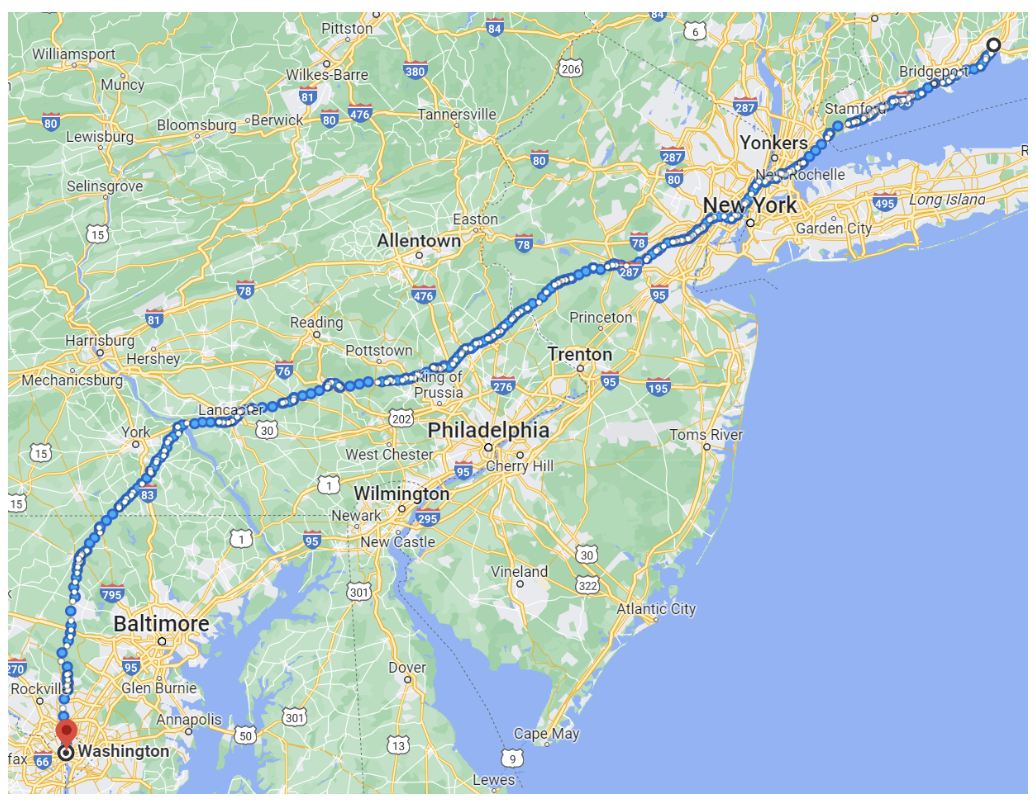
Image 3. RTT client to microservice via Kafka, 2.6ms or 330 miles
Reviewing the client Kafka’s allocation rate we found a substantial amount of garbage collection occurring, with Flight Recorder showing an allocation rate of about 6.5GB per second. This level is normal for *most* Java applications, but it’s not essential and must be avoided when pursuing the lowest possible latencies.

Image 4. Memory Usage in Kafka
On the other hand, using Chronicle Queue for the same benchmark, the 99th percentile latency was just 3.67 microseconds – almost 700 times less, and the equivalent of sending a signal across Battery Park:
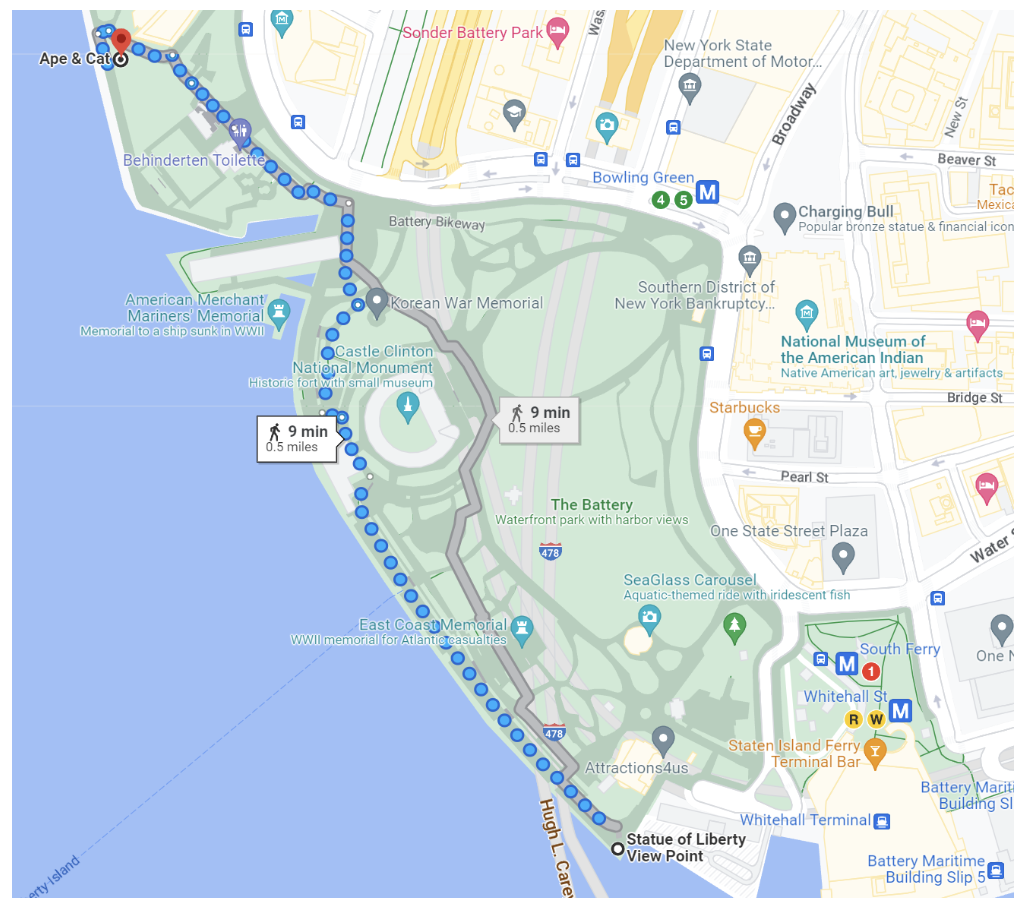
Image 5. RTT via Chronicle Queue, 0.003ms or 800 yards
When looking into the allocation rate with Chronicle Queue, it highlighted that most of the garbage was due to Java 8’s flight recorder. With Java 17’s flight recorder this was dramatically reduced:

Image 6. Memory Usage in Chronicle Queue
Accidental Complexity in Chronicle Queue
In Image 7 we can see that open source Chronicle Queue in Java still has some accidental complexity in the higher percentiles. Meanwhile, there are commercial C++ and Rust versions, and these have much more consistent latencies:
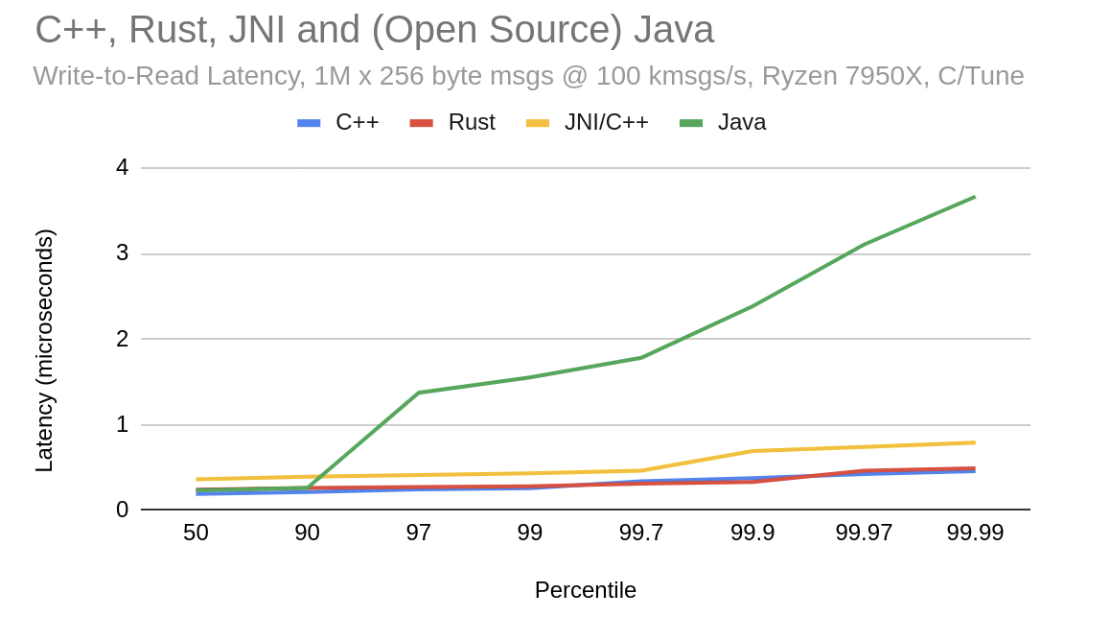
Image 7. Chronicle Queue Enterprise, Chronicle Queue Open Source, Multi Language
99% Accidental Complexity
Back to the latency comparison from earlier; as Chronicle Queue was 700 times faster – or that the same task could be completed in 1% of the time -it indicated that 99% of the latency was accidental, for the purposes of this benchmark.
Determining the amount of accidental complexity in a system is challenging, but a comparison between different strategies can provide some indication. Ultimately, any differences in completing the same tasks could be considered ‘accidental’. It is also worth noting that just because one strategy may be faster, it does not inherently mean that there is not further, or different accidental complexity in that too.
If you are interested in finding out how your system’s latency could be reduced by investigating potential accidental latency, book a demo with our experts, or find out more on our website.
Resources
Chronicle Queue Enterprise: https://chronicle.software/queue-enterprise/
Book a demo: https://chronicle.software/demo/?product=queue-enterprise