Object pools were popular before Java 5.0, however, more efficient allocation made most of these pools a needless complication. Can an Object Pool still make sense and how fast do they need to be?
Overview
Up to Java 5.0 using object pools could significantly improve performance. However, from Java 5.0, the cost of using naive object pools was often worse (and more complicated) than just allocating new objects all the time. However, if you work in a low latency environment and you want to keep allocations low, is there a way to make an object pool lightweight enough to make sense.
A common use of a low-level object is in the creation of Strings esp as input. Whether you have a service reading data from the network or loading data from a database or file, you are likely to use a lot of Strings. While there are tricks to avoid using Strings, most of the alternatives lead to unnatural Java code which is ugly and harder to maintain. It would be much better if there was an efficient way to reuse Strings (assuming a high rate of duplication)
The test
This test assumes we have some data in native memory (from a TCP socket or a file), and we have the option to avoid copying the data into a byte[] before creating a String.
For different lengths of bytes (1, 2, 4, 8, 16, 32) we use JMH to benchmark how long it takes to provide a matching String.
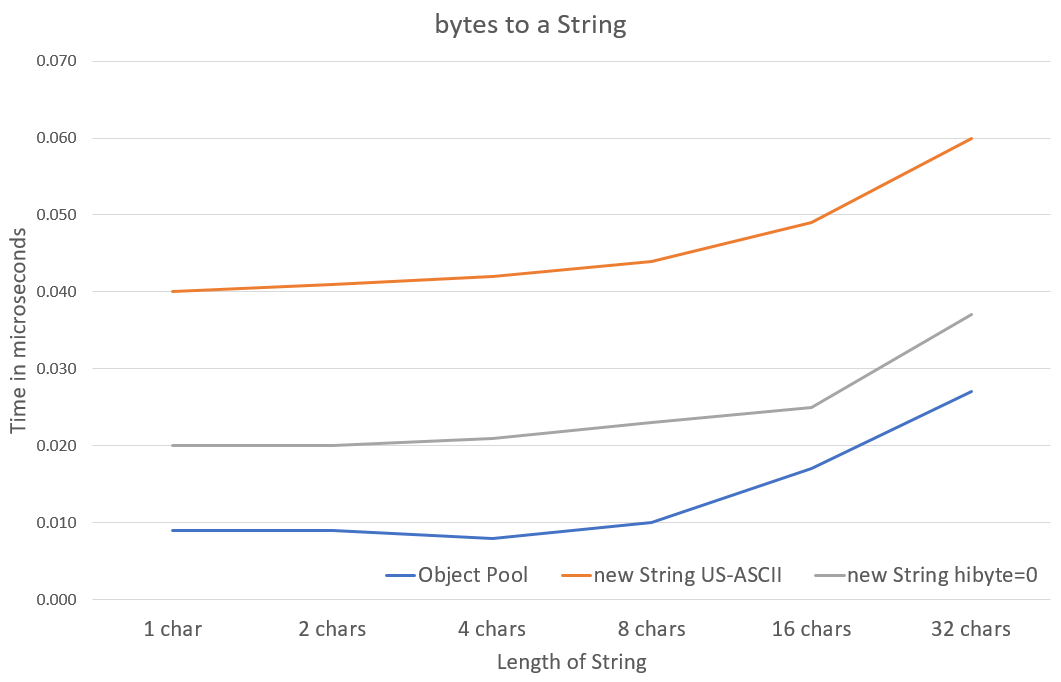
“Object Pool” uses an object pool for the bytes converted into a String.
“new String US-ASCII” copies the data to a byte[] and uses US-ASCII encoding to create the String.
“new String hibyte=0” copies the data to a byte[] and uses a deprecated constructor to set the hi byte to 0 create the String.
The Source code is available here ObjectPoolMain.java
The results
The average time to use the Object Pool was around 9 nano-seconds for short strings of up to 8 characters. About half the saving comes from avoiding the need to copy the data to a byte[] first. Also avoiding the use of even a trivial Charset character encoding also saved a significant amount.
Why use an Object Pool at all?
In this case the main reason is to avoid creating objects. If the String can be reused, it can dramatically reduce the garbage produced. Most of the time, only new Strings take space, rather than every String your use and this can be a 90% reduction in memory use and garbage production.
Conclusion
For some use cases, an Object Pool is fast enough, possibly faster when it is has been optimised to minimise copies and supporting functions like character encoding.
| The library used only supports ISO-8859-1 and UTF-8, so if you need another character encoding it would be significant work or use would have to use the standard functions. |