This note briefly describes some early performance comparisons between the Java and C++ implementations of QueueZero. The C++ version is a fully functional port of QueueZero, and is fully interoperable with Java Appenders and Tailers.
Two tests were run:
1. A write of a single long value (ie startWrite – writeLong – endWrite) repeated 50,000 times, with summary statistics gathered from 10,000 runs
2. A bulk write of 500,000 long values within a single startWrite/end write, with summary statistics gathered for 10,000 runs
QueueZero includes a timestamp within the header for each write, hence the main difference between these two tests is the first includes a clock read per long value written, whereas the second includes just the one clock read per 500,000 long values written, and consequently provides a more direct insight to the raw queue performance.
Summary results for Test 1:
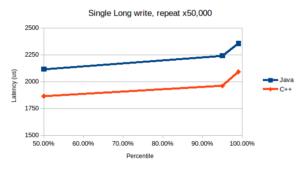
Summary results for Test 2:
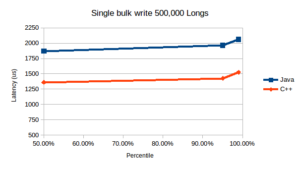
The results show around a 12% improvement for C++ latencies compared to Java for the single writes, with around a 25% improvement for bulk writes. This difference in relative improvement between the two tests reflects the fact that a sizeable proportion of the individual write timings in Test 1 is set by the fixed overhead to read the system clock – which is more or less the same between Java and C++. By contrast, for Test 2 the clock read is a much smaller contributor to the overall latency of the bulk write, allowing the raw difference between Java and C++ to show more clearly.
The bulk writes in Test 2 show a raw queue latency of ~4ns per write for Java (bytes.writeLong), versus ~2.5ns per write for C++, which is broadly consistent with previous queue comparisons.
The qualitative behaviour between the Java and C++ runs is notably consistent across the range of percentiles over both tests (albeit there are only a small number of data points for these preliminary runs). Looking into the performance differences a little more, for Test 1 the bulk of the improvement in the C++ version comes from exploiting the lower-level control C++ exposes for atomic operations – and in particular the ability to use acquire/release semantics which avoids the need for a full mfence on x86 for synchronising calls per queue write. By contrast Java natively uses totally-ordered sequentially consistent atomic operations which impose an mfence per write (even though this is overkill for the kind of synchronisation needed between QueueZero Appenders and Tailers).
For Test 2, the C++ implementation benefits from the templated design which in turn leverages static polymorphism to reduce runtime virtual calls. While some virtual calls remain, this design significantly reduces the abstraction penalty, in particular enabling greater inlining opportunities for the compiler.