Benchmarks have a natural lifespan that can be improved with more modern hardware. This benchmark was performed on March 11, 2020. Please don’t hesitate to contact us if you have questions about how Chronicle FIX will perform today.
Introduction
This benchmark demonstrates the performance of Chronicle FIX with varying numbers of connected sessions.
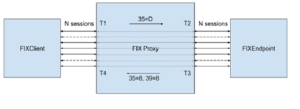
FIX Client opens a configurable number (N) sessions with an intermediate FIX Proxy
As shown in the above diagram, a FIX Client opens a configurable number (N) sessions with an intermediate FIX Proxy. The Proxy in turn accepts N sessions from a downstream FIX Endpoint.
The proxy sessions between client and endpoint are 1-to-1, with the message flows are as follows:
• The FIX Client sends a NewOrderSingle (35=D) to the FIX Proxy
• The Proxy receives and parses the NewOrderSingle, and invokes a callback handler which forwards the message on to the FIX Endpoint
• The Endpoint receives and parses the NewOrderSingle and responds by sending a Rejected ExecutionReport (35=8, 39=8)
• The Proxy receives and parses the ExecutionReport, and invokes a callback handler which forwards the message on to the FIX Client, completing the round trip
The N sessions are completely independent, and serviced concurrently by the FIX Proxy.
Timestamps are captured as follows:
• T1 – nanosecond timestamp immediately after socket read inbound from client
• T2 – nanosecond timestamp immediately after socket write outbound to endpoint
• T3 – nanosecond timestamp immediately after socket read inbound from client
• T4 – nanosecond timestamp immediately after socket write outbound to client
Plots are given below for the NewOrderSingle latency (T2 – T1) and the ExecutionReport latency (T4 – T3) for varying numbers of concurrently connected clients.
Results
The following plots show results for 1, 5, 10, and 25 clients/endpoints, with the benchmarks run on a 2 x 12 core E5-2650 v4 @ 2.2GHz with 128GB RAM. Cores 12-23 were isolated using isolcpus.
A total of 3,000,000 NewOrderSingle messages were entered by the client at a rate of 10,000 msgs/s. Where multiple sessions were connected, messages were sent at the same overall rate, with subsequent messages sent on successive sessions round-robin (ie the effective rate per session was 10,000/N).
Some observations:
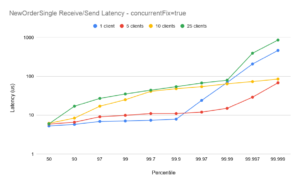
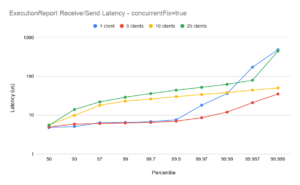
Scaling from 1-5 clients
With the concurrentFix option set to true, the plot for 5 clients shows similar end-to-end latencies as for a single client, demonstrating good scaling – especially for the ExecutionReport flow. It should be noted in particular that the outliers for 5 clients are significantly better than for 1 client (see below).
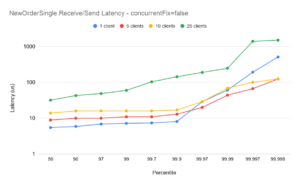
Scaling for 10 clients
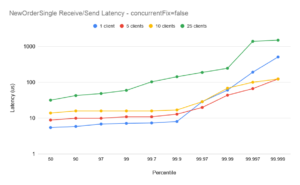
The plots for 10 clients with concurrentFix false show lower latencies than with concurrentFix true. While running with concurrentFix true would be expected to show better scaling (see the 1-5 case above) in this case the comparison is reversed. This is due to excessive demand on the available CPUs – the machine was over-committed – and the plots are included to show the importance of correct tuning. (Note also, in these tests all client sessions as well as the FixProxy are being run on the same machine. In practice the FixProxy would normally be on a separate host, reducing the overall CPU demand). Chronicle FIX can support large numbers of clients with low-latency, but it is important that the environment is correctly configured. Chronicle can help with bespoke tuning to help achieve optimal latencies on a case-by-case basis.
Scaling for 25 clients
The plots for 25 clients with concurrentFix true are again better than the equivalent plots with concurrentFix false. Comparing this with the 10 client case above, the machine is again somewhat over-committed on CPU demand, however even with that the balance favours running with concurrentFix as the non-concurrent run simply has insufficient bandwidth to service the sockets sufficiently quickly to avoid delays. Again, this is included to underline the importance of understanding the realistic demands on a Chronicle FIX installation, and tuning an environment carefully to extract maximum performance.
Outliers for 1 client
In all plots the outliers for the single session case (blue plots) are higher than for the 5- and 10- session case. The reason for this is that at 10,000 messages per second, the message spacing on the single session is 100us, and while the majority of messages are handled well within 100us, transient outliers will cause some queueing of messages in the TCP buffer. Even though those subsequent messages are handled with low latencies, the queueing overhead causes the overall end-to-end to momentarily spike. This illustrates one of the main benefits of running with several concurrent sessions (and concurrentFIX true): while the end-to-end latencies can be slightly higher with more sessions[†], the outliers are more controlled.
[†] up to some upper limit of sessions; in these examples somewhere between 10 and 25
ConcurrentFix=true
NewOrderSingle Latency
ExecutionReport Latency
ConcurrentFix=false
NewOrderSingle Latency
ExecutionReport Latency
Tuning Recommendations
To help minimize jitter, this test should be run with CPU isolation, with more cores reserved for higher concurrent sessions as described above. For example, to isolate cores 2 and 3 on Linux the following should be added to the boot command line (viewed using /proc/cmdline). A reboot will be required for isolcpus changes to take effect.
isolcpus=2,3
Power management and the spectre meltdown patch should also be disabled where possible:
Turn off power management and the spectre/meltdown patch
spectre_v2=off nopti processor.max_cstate=1 intel_idle.max_cstate=0