What sets Chronicle Queue apart is that it’s a very lightweight way to buffer large volumes of data for hours, weeks, or years without pushing back on the producer. It’s not limited by heap size, or memory size, only by available disk space.
For example, one of our users has recorded every tick of the Options Price Reporting Authority (OPRA) feed for eight years, allowing them to reprocess or replay that data from any point. The OPRA feed now peaks at 120 million messages per second.
In this article, we explore the world of Chronicle Queue to understand how it revolutionises Big Data solutions and look at what distinguishes it from other data messaging systems.
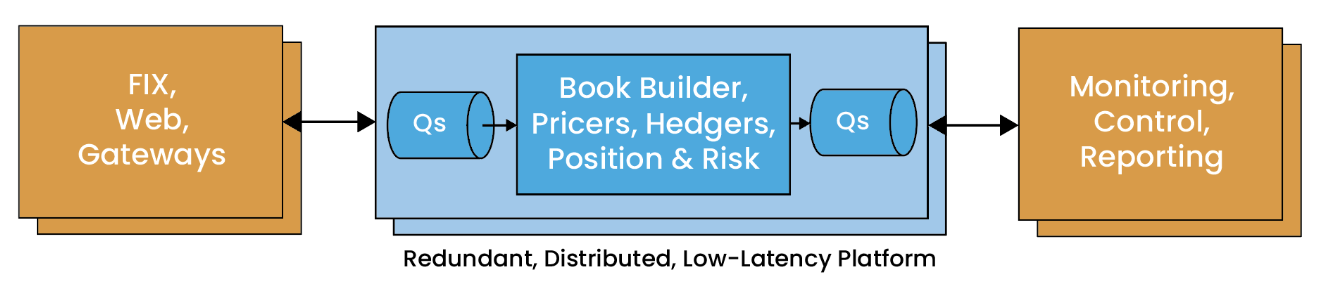
Image 1. Simplified Network diagram, with the messaging system Chronicle Queue
What is Chronicle Queue?
Chronicle Queue is a persisted journal of messages that can handle concurrent writers and readers across multiple JVMs on the same machine. Unlike other solutions, Chronicle Queue retains every message, which has several advantages. For example, messages can be replayed as many times as needed, making it ideal for debugging. It also reduces the need for extensive logging, significantly speeding up your applications.
To illustrate this with a real-world example, a client’s trading system initially achieved an average latency of 35 microseconds without using Chronicle Queue. However, switching to Chronicle Queue, reduced their latency by 34%, resulting in an impressive average latency of just 23 microseconds. This significant improvement highlights Chronicle Queue’s ability to dramatically enhance system performance, particularly in latency-sensitive applications like trading systems.
What Sets Chronicle Queue Apart?
- Speed: Chronicle Queue is built to handle hundreds of thousands of messages per second, even supporting multi-second bursts into the millions of messages per second. Some users have reported handling bursts of 24 million messages per second with a cluster of 6 servers.
- No Flow Control: Unlike many other messaging solutions, Chronicle Queue operates without flow control between producers and consumers; a “producer-centric” solution.
- Producer-Centric Solution: Chronicle Queue’s producer-centric approach ensures that the producer is never slowed down by a slow consumer. This has various advantages, including bug reproduction, and independent microservice testing, and seamless service restarts and upgrades.
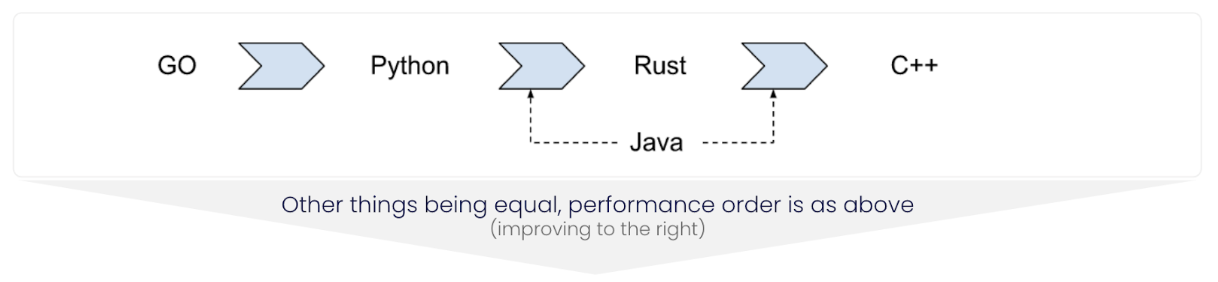
- Multi-language Offering: Chronicle Queue is now offered in multiple languages, including Java, Python, C and Rust, as well as a Proof of Concept in Go, which ensures efficient interoperability and the ability to leverage the strength of each language.
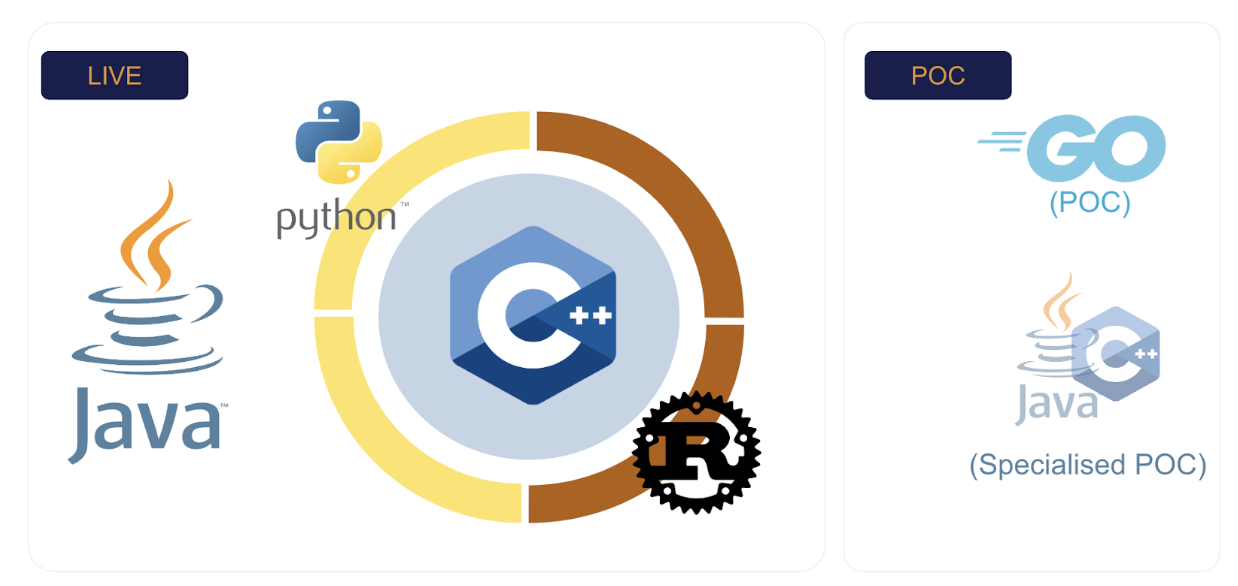
Java for Low Latency?
Chronicle Queue leverages Java’s abstraction layer and protection to achieve impressive performance. It supports data structure sharing in memory for multiple JVMs, eliminating the need for TCP-based data sharing.
Minimising Garbage
For ultra-latency-sensitive systems, minimising garbage collection is crucial. Chronicle Queue offers strategies to achieve this, such as keeping the allocation rate below 300 KB/s and translating between on-heap and native memory without generating temporary objects. Object pooling and support for reading into mutable objects further contribute to garbage reduction.
Conclusion
Chronicle Queue is an enabling technology for high-performance, Big Data applications with microsecond processing times. Its unique features, speed, and garbage reduction strategies make it a top choice when performance is critical.
For a free demo and details on how to get started with Chronicle Queue, contact us.